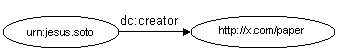|
 |
| DOCUMENTATION |
| FLEXIBLE METADATA STORING - ELSEM REPORT - |
| - Introduction |
| - Storage alternatives for semantic metadata |
| - OpenCyc |
| - Overall description of the SLOR prototype |
| - Integrating the large commonsense ontology |
| - Problems found |
| - Final Proposed Architecture |
| DOWNLOAD |
| WORKING GROUP |
| Further Work |
| Storage alternatives for semantic metadata |
|
In
order to store learning object metadata records, the two main research
directions focused during the prototype construction are the following:
- Semantic Web approach: In the same direction of the semantic web vision, we have used several semantic web technologies in order to achieve flexibility within learning object metadata. - Common Sense within metadata records: In order to enable the common sense reasoning from learning object metadata, we have made use of the OpenCyc Knowledge base. This new approach strengthens the flexible schema used within learning object metadata records and provides new opportunities for reasoning and inference. RDF STORAGE TECHNIQUES The RDF data structure is a directed graph. Each node represents a resource (subject) that is linked to other resource (object) through a direct arc labeled with a third resource (predicate).This basic representation has a semantics defined by the statement “subject has a property (predicate) valued by an object”. This structure is called a “triple” and is formally declared as {<subject>,<predicate>,<object>} , where: - Subject: is an RDF URI reference or a blank node. Figure 1 shows an example of triple
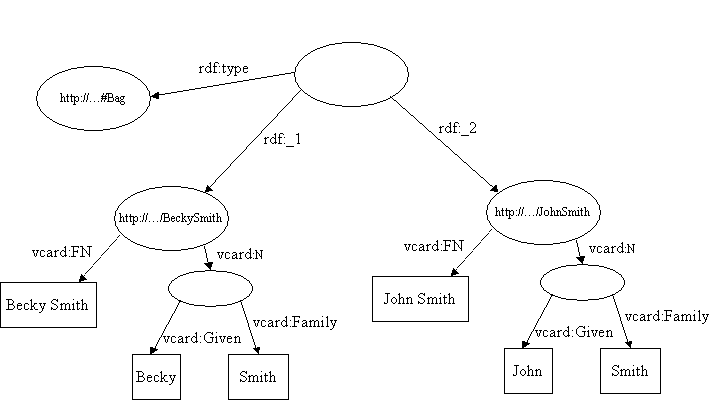
-- figure 1 -- A collection of triples builds a graph that represents an RDF model. There are three ways to store an RDF model: in memory, in a file or in a database. In all these cases, the triple is the basic piece to store a RDF model. The following sections detail how to store this model. In-Memory Storage The graph is the best structure to store RDF in memory. Each node describes either a resource or a literal; all resources can be linked to other nodes through a property.
-- figure 2 -- In-File Storage The RDF/XML Syntax specification (Beckett and McBride, 2004) proposes an XML syntax for encoding RDF graphs. However, the standard RDF/XML mapping is unsuitable for this purpose since multiple XML serializations are possible for the same RDF graph, thus making retrieval complex.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about= "http://www.myserver.com/XMLWebPortals.html"> <dc:title>BUILDING WEB PORTALS WITH XML</dc:title> <dc:creator rdf:resource="urn:jesus.soto:upsam.net"/> </rdf:Description> </rdf:RDF> N3 (Bernes Lee, 1998) is a language that offers a compact and readable alternative to RDF’s XML syntax, keeping its expressiveness. Simple and consistent grammar, readable and URI abbreviation are some of its most outstanding features. @prefix dc: <http://purl.org/dc/elements/1.1/>
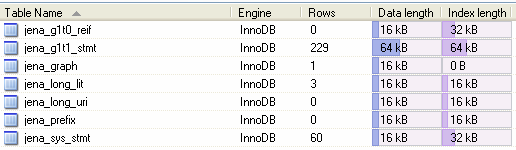
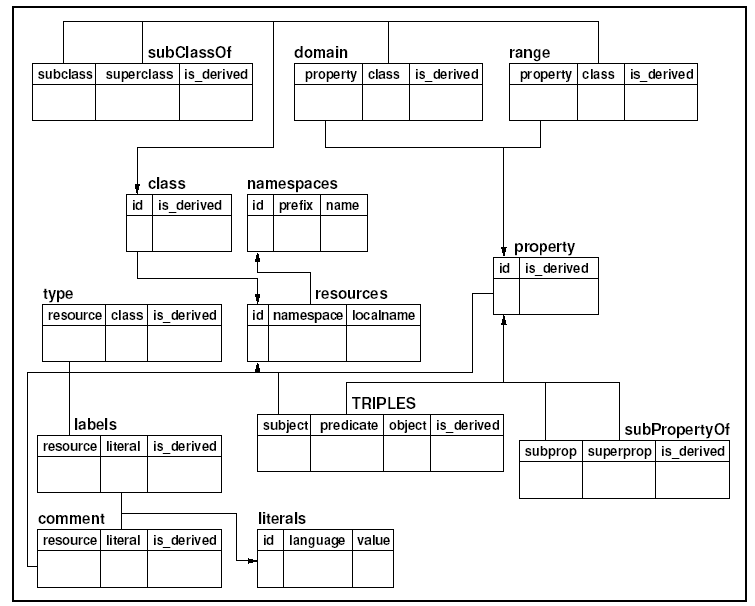
. In-Databases: Persistence Frameworks - Jena RDF Storage Jena is a framework for Semantic Web Development. It is a widely used, open-source project implemented in Java. The Jena architecture provides an abstract RDF model to manage an internal graph that store the RDF model. The applications typically interact with an abstract Model which translates higher-level operations into low-level operations with triples stored in an RDF Graph. The Jena database subsystem implements persistence for RDF graphs using a relational database through a JDBC connection. The experience with Jena1 (first version), exposes that the uses of a denormalized relational schema reduce response times (Wilkinson et al., 2002) The current version of Jena (second version, called Jena2) trades-off space for time. Both resource URI and simple literal values are stored directly in the statement table (stmt table). In order to distinguish literals and URIs, columns values are encoded with a prefix (such as Uv::, Lv:: ) that indicates the type of value. If the length of a literal value exceeds a threshold, the literal value is stored in a separated table (long lit table). By storing values directly in the statement table it is possible to perform many find operations without a join. When the size of the statement table is a problem, Jena2 provides several options to reduce it, such as, compression of namespaces (by defining a prefix in the long uri table and using these prefix like a reference to the namespace), storing the long values only once (by deriving to the long lit table) or using the property tables. - Sesame RDF Storage Sesame is an open source RDF database with support for RDF Schema inferencing and querying information. In Sesame, there are two different approaches to store RDF in databases: strictly relational schemas or object relational schemas. Strictly Relational Schema: the basic properties described by the RDF Specification are transformed into database tables (figure 4). This approach uses a fit schema, which constitutes an advantage to performance when an rdf model often changes. In order to reduce both the overhead and the database space, all resources and literals are encoded by an id. Depending on whether a particular statement was explicitly asserted or derived from the schema information, an extra column ‘is_derived’ is added where appropriate. Object Relational Schema: The progress in the development of Sesame has showed some RDF store features. The performance of Sesame together with object-relational DBMS has been proved in several studies (Broekstra, Kampman and Harmelen, 2005; (other)). These studies agree in the same conclusion: The performance is very low if the database system creates a table whenever a new class or property is added, therefore in scenarios where the schema changes often, the RDF graph direct mappings are not valid in the RDF storage over object-relational DBMS. A study realized with PostgreSQL in (Broekstra, Kampman and Harmelen, 2005) uses a different approach (similar to Jena) in witch all RDF statements are inserted in a single table with three columns: “Subject, Predicate, Object”. In scenarios where the schema changes often, this approach is better than the object relational schema.
The Sesame’s study reflects the fall down performance using
RDF persistence over ODBMS. The Oracle approach to store RDF utilizes
a new object type (SDO_RDF_TRIPLE_S) for storing RDF data. The RDF
object type is built on top of the Oracle Spatial Network Data Model
(NDM) (ref oracle). NDM is Oracle’s optimal solution for storing,
managing, and analysing networks or graphs in the database. Triples
are parsed and stored in the system as entries in the NDM node$
and link$ tables. Nodes in the RDF network are uniquely stored and
reused when encountered in incoming triples. A key feature of RDF
storage in Oracle is that nodes are stored only once – regardless
of the number of times they participate in triples. Besides, only
one new triple is stored for each reification - Oracle uses XML
DB DBUri to reference the reified triple in the database. This approach
minimizes storage and reduces performance overhead for querying.
However is a complex model to manage RDF information, the user of
the Oracle RDF objects should carry out all low-level operations.
Finally, is not available yet a persistent framework to manage the
RDF information store in Oracle.
|